Exponential Smoothing
Exponential Smoothing is a commonly used time series forecasting method for smoothing and predicting data. It assigns different weights to historical data, with more recent data receiving higher weights and older data receiving lower weights. SPSSAU offers three types of exponential smoothing: Simple Exponential Smoothing, Double Exponential Smoothing and Triple Exponential Smoothing. It is located in SPSSAU -> Comprehensive Evaluation -> Exponential Smoothing.
SPSSAU Operations
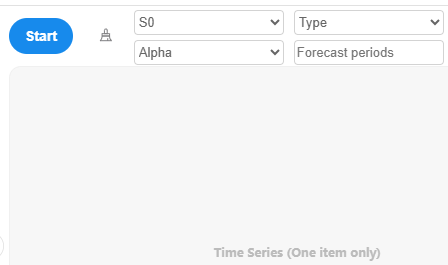
To perform the analysis, drag the time series data (only one item) into the right-hand box and click 'Start'. SPSSAU includes four parameters:
Initial Value (S0): Default is 'Auto', where the algorithm selects the optimal initial value based on the Root Mean Square Error (RMSE). Other options include the first period, the average of the first 2, 3, 4, or 5 periods.
Alpha: Default is 'Auto', where the algorithm selects the optimal alpha based on RMSE. Options range from 0.05 to 0.95 in increments of 0.05.
Smoothing Type: Default is 'Auto', where the algorithm selects the optimal type based on RMSE. Options include Simple, Double, and Triple Smoothing.
Backward Forecast Periods: Default provides forecasts for the next 12 periods, but users can customize this value.
SPSSAU Data Format
Exponential Smoothing is best suited for datasets with a small sample size. If the dataset includes a time term, it should be sorted sequentially but does not need to be included as an analysis item (it can be placed in the 'Label').
Algorithm
Simple Exponential Smoothing
Simple Exponential Smoothing is a basic time series forecasting method. The calculation steps are as follows:
1.Initialize the Smoothed Value
Choose the initial smoothed value S1, typically the first observed value x1:S1 = x1, which can be selected automatically by SPSSAU or manually.
2.Set the Smoothing Constant
The smoothing constant, α, ranges between 0 and 1. A larger α makes the model more sensitive to recent data.
3.Compute the Smoothed Value
For each time point t (t > 1), calculate St: St = αxt + (1 - α)St-1.
xt: actual value at time t.
St-1: smoothed value at time t - 1
4.Compute Forecast Values
For time t + 1, the forecast value is:
5.Compute Forecast Errors
Forecast error et is defined as: Absolute error (AE):
6.Evaluate Forecast Accuracy
Forecast Accuracy is assessed using RMSE, MSE, MAE, or MAPE:
Double Exponential Smoothing
Double Exponential Smoothing is suitable for data with linear trends, such as per capita GDP.
1.Initialize the Smoothed Value
Choose the initial smoothed value S1, typically the first observed value x1:S1 = x1, which can be selected automatically by SPSSAU or manually.
2.Compute Smoothed Values
: Simple Smoothing, : Double Smoothing. xt: actual value at time t, α: corrected error.
3.Compute Trend
When applying Double Exponential Smoothing to linear trend data, its essence is to identify a linear regression trend line. Mathematically, this can be represented by the following formula: , where T represents the predicted value for the future period T, and at and bt are the parameters of the linear regression trend line. These parameters are calculated using the following formulas: Out-of-sample forecast values (prediction values) are computed using: In-sample forecast values (fitted values) are computed as:
4.Compute Forecast Errors
The forecast error et is defined as the difference between the actual value and the predicted value: The absolute error (AE) is calculated as:
5.Assess Forecast Accuracy
Forecast accuracy can be evaluated using RMSE, MSE, MAE, or MAPE: n: the number of forecast points, et: error.
Triple Exponential Smoothing
Triple Exponential Smoothing extends Double Exponential Smoothing by adding another level of smoothing, making it suitable for time series with a curvilinear growth trend, such as per capita GDP data. The calculation process is as follows:
1.Initialize Smoothing Values and Seasonal Index
Choose the initial smoothed value S1, typically the first observed value x1:S1 = x1, which can be selected automatically by SPSSAU or manually.
2.Compute Smoothing Formulas
: Simple Smoothing, : Double Smoothing. xt: actual value at time t, α: corrected error.
3.Compute Trend
When applying Triple Exponential Smoothing to curvilinear trend data, it essentially finds a quadratic regression trend line. Mathematically, this is given by: at,bt, and ct are parameters of the quadratic trend line, computed as: Out-of-sample forecast values (prediction values): In-sample forecast values (fitted values):
4.Compute Forecast Errors
The forecast error et is defined as the difference between the actual value and the predicted value: The absolute error (AE) is calculated as:
5.Assess Forecast Accuracy
Forecast accuracy can be evaluated using RMSE, MSE, MAE, or MAPE: n: the number of forecast points, et: error.
References
【1】The SPSSAU project (2024). SPSSAU. (Version 24.0) [Online Application Software]. Retrieved from https://www.spssau.com.
【2】周俊,马世澎. SPSSAU科研数据分析方法与应用.第1版[M]. 电子工业出版社,2024.